Abstract
Large language models write fluent research prose, yet they fabricate figures, lean on a single source, and state estimates as fact. The usual response is a stronger model or more agents. We argue that the binding constraint is epistemic discipline, not capability, and that the discipline can be written into a doctrine and then enforced by a deterministic gate. We study a production multi-agent research system whose agents share such a doctrine, and we build a five-rung ablation ladder from a bare prompt to a full pipeline with an independent critic and an unknown-unknowns moderator. We score each output on two axes: a deterministic linter that measures doctrine form, and a judge, blind to which pipeline produced which brief, that rates factual grounding. Adding the doctrine prompt produces a large, completely separated gain in form (permutation p = 0.0045), but it does not significantly improve correctness over the control (p = 0.127). Only enforcement improves correctness, over both the control and the prompt (critic over prompt, p = 0.0006). Prompting takes the form of a grounded report. Only enforcement buys the substance. The ranking holds under a six-judge panel across three providers, under a model-free web-search factuality check, and under a full replication of the latter on a second base model, GPT-5.5, where it reproduces with complete separation. The contribution is compiled, enforceable doctrine, distinct from the prompt that states it.
1. Introduction
A research agent that browses the web and writes a report is now a routine product. The quality problem is also routine. The agent produces a confident number with no source. It cites the blog that repeated a figure rather than the filing that produced it. It reports a survey result with the same certainty as a sales figure. It treats the absence of competitors as proof of a green field. None of these failures is exotic. All of them survive a strong model, because a stronger model is still happy to write a fluent unsupported sentence.
The reflex in multi-agent work is to add capability. Use a larger model. Add more agents and more search passes. We take a different position. We claim that the dominant failures above are failures of discipline and of state, not of reasoning, and that the cheapest durable fix is to write the discipline down and then enforce it.
This paper studies the claim within a working system. The system carries a written research doctrine that every agent inherits at compile time. The doctrine names two orthogonal axes for grading evidence. The first is behavioural, what a number measures, ordered as stated preference, below search behaviour, below sales. The second is provenance, who measured it, ordered as first party above partial above third party. A survey result and a transaction record can both be first-party, yet they do not carry the same weight, and the doctrine forces the author to state both axes on every quantitative claim. The doctrine adds a citation rule that separates cited fact from labelled estimate from the agent's own inference. It requires triangulation across at least two independent source classes. It requires that every hypothesis state what would confirm it and what would disconfirm it. It requires four to six named stakeholder perspectives, derived before retrieval and reported as coverage afterwards.
A doctrine that lives only in a prompt is a suggestion. The system also compiles the doctrine into a deterministic checker that runs as a ship gate. The checker is not a language model. It reads a finished deliverable and asks, for every paragraph that contains a figure, whether that paragraph carries its own dual-tier label and its own source and date. It blocks the output if any load-bearing figure is unlabeled, undated, or unsourced. On top of the checker sits an independent critic that revises to close the gaps, and a moderator that hunts for the angles and contradictions the first pass missed.
We ask three questions. RQ1: At a fixed model and fixed tools, does writing the doctrine into the prompt change the output, and by how much? RQ2: Is the enforcement layer, the deterministic gate and the independent critic necessary, or does a well-written prompt already do its job? RQ3: Does a cheap deterministic check of doctrine form track the actual correctness of the report, or can the two come apart? In short, the prompt produces a large and significant gain in the form of the output; enforcement is necessary because the prompt buys form without buying correctness, and a cheap form check correlates only moderately with correctness. Two of our early estimates moved toward the null under replication, and we report both corrections in full.
Our contributions are:
- A concrete, reusable epistemology for research agents: the dual evidence hierarchy and the rest of the doctrine (Section 3).
- A method for turning that doctrine into a deterministic, enforceable ship gate rather than a style note (Section 3).
- A five-rung ablation ladder evaluated on two independent axes, a deterministic shape score and a blind correctness rating, with exact tests and effect sizes (Sections 4 and 5).
- Evidence that the doctrine prompt produces a large, stable shape gain at fixed capability, that the prompt alone never clears the strict gate, and that only enforcement both breaks the gate and tops the blind correctness ranking (Section 5).
- A six-judge cross-provider reliability panel and a full replication of the ladder on a second base model that retires the single-model exposure (Sections 5 and 6).
2. Related Work
Our perspective engineering and our moderator pass build on the STORM line of work on knowledge curation [1], which generates an article by first asking questions from multiple perspectives and then synthesising cited prose, and on its Co-STORM extension [2], which adds a moderator that surfaces overlooked directions in a collaborative setting. We adapt the perspective-first idea and the moderator role into a market-research pipeline and pair them with an enforcement layer. The adaptation, not the primitive, is ours.
A large body of work evaluates attributed generation. Frameworks for long-form question answering with citations measure citation precision and recall through entailment between a statement and its cited support [3]. Long-form factuality work decomposes a text into atomic claims and verifies each against retrieved evidence [4, 5]. These are correctness instruments. Our deterministic linter is deliberately weaker and cheaper. It checks whether the scaffolding for grounding is present, not whether each claim is true, and we treat that gap as a first-class limitation rather than hiding it. Our blind judge is closer in spirit to the factuality instruments, and our results show the two kinds of measurement can disagree in informative ways.
Work on deep research agents has produced benchmarks that test whether an agent can find a hard fact on the live web or assemble a correct closed-form answer. Those benchmarks ask whether the agent gets the answer. We ask a different question, whether the agent's report is honestly graded and honestly sourced, which a benchmark of verifiable answers does not capture.
Our evaluation depends on a model judge, and the meta-evaluation literature documents that model judges carry position, verbosity, and self-preference biases. We control position bias by shuffling the briefs behind anonymous labels, and we keep the judge blind to the producing pipeline. We do not claim to have removed judge-family bias, and we bound it with a panel of six judges across three providers and a committed inter-rater statistic (Section 5).
3. System
The system under study is the research team of a larger multi-agent workforce, which we refer to as Marg. A research orchestrator routes a question through a fixed sequence: it reads prior context, derives the named perspectives, classifies the question, spawns the right specialist, parses a structured handoff, runs a moderation pass for missed angles, runs an independent critic on strategic work, and scores the synthesis against the doctrine before delivery. The agents do not read a shared file at runtime. The operative doctrine is concatenated into each agent at compile time, so the discipline travels with the prompt. We describe the four components that the ablation isolates.
The dual evidence hierarchy. The core of the doctrine grades every quantitative claim on two axes at once and writes both labels next to the number. The behavioural tier records what the number measures, with stated preference weakest, search behaviour stronger because it is revealed at scale, and sales or committed capital strongest. The provenance tier records who measured it, from first party down to single-source speculation. The two axes are orthogonal. The pairing prevents the common error of stating a survey result with the confidence due to a transaction.
Citation and triangulation. The doctrine separates three statement types and forbids blurring them: a cited fact carries a primary source, a labelled estimate is named as an estimate, and an inference is the agent's own reasoning, marked as such. No load-bearing conclusion may rest on one source class, and when sources conflict, the agent surfaces the conflict and the likely reason rather than averaging the numbers.
Falsification and perspectives. Every hypothesis must state its disconfirmer, and a datapoint that cuts against the thesis is honoured rather than buried. Before retrieval, the orchestrator derives four to six named stakeholder perspectives, such as the sceptical buyer, the incumbent product lead, and the bear-case analyst, and threads them through the work. An unaddressed perspective is reported as a named gap.
Enforcement and statefulness. A written rule that no one checks will drift. The system compiles the doctrine into a deterministic linter that runs in the ship gate. The linter splits the deliverable into paragraphs, finds those that contain a quantitative claim, and requires each such paragraph to carry its own dual-tier label and its own source and date. It hard-fails the build on an unlabeled, undated, or unsourced figure. Because it is deterministic and uses no model, it is safe to run as a pre-push gate. Above the linter, an independent critic re-reads strategic deliverables, checks claims against the cited sources, and revises to close gaps without weakening conclusions. A moderator runs an unknown-unknowns pass for retrieved-but-unused material, unexplored adjacent angles, and unchased contradictions, then closes the highest-value gap. The system also persists a hypothesis ledger across sessions, and invalidated hypotheses are kept with the reason they failed rather than deleted, so a later session does not relitigate a settled question.
4. Experimental Method
We build a five-rung ablation ladder. P0 is a control with a neutral research prompt. P1 adds the doctrine as a prompt. P2 adds the hypothesis ledger. P3 adds the independent critic who revises to clear the gate. P4 adds the unknown-unknowns moderator on top of enforcement. Every rung runs on the same model family and the same tools, live web search and fetch only. The premium research connectors were unavailable, which lowers the ceiling for every rung equally and so does not bias the comparison.
We run the ladder on three contamination-controlled questions drawn from a benchmark of post-cutoff prompts, one each for the validate, ideate, and differentiate intents. Each benchmark item carries a minimum perspective count, mandatory lenses, and the signal classes a good answer should reach. The benchmark has since been expanded to forty items, used in the second-model replication of Section 6, with the schema unchanged.
We score every deliverable two ways. The first instrument is the production doctrine linter of Section 3. It returns a shape score out of 100 and a hard-fail flag, and it is the same checker the ship gate uses, so the experiment measures exactly what production measures. The second instrument is an independent correctness judge. For each question, we anonymise the five rung-deliverables behind shuffled letters, withhold the mapping, and ask a judge who does not know which pipeline produced which brief to rate each on grounding, citation quality, calibration, and the absence of unsupported figures. We control position bias with a seed-shuffled assignment, and the judge may spot-check at most two suspicious figures on the live web. To test the reliability of this instrument, two further judges from different models, Claude Sonnet and Claude Haiku, rather than the Claude Opus of the first judge, independently rated the same first-run briefs under the same rubric. To test whether the judge family is the confound, three more judges from other providers rated the identical anonymised briefs under the identical four-part rubric, blind to configuration: GPT-4.1 and Gemini 2.5 Flash through the OpenAI and Google APIs at temperature zero, and GPT-5.5 reached through a ChatGPT-authenticated command-line tool. We report agreement across all six judges from a committed deterministic script.
To estimate run-to-run variance on the rungs that carry the headline effects, we replicate the doctrine and enforcement rungs to nine runs each, three per question.
Statistical analysis. With a small sample, the right tools are exact tests and effect sizes, not asymptotic approximations. For each contrast, we report an exact permutation test on the mean difference, which enumerates every label assignment and makes no distributional assumption, together with Cliff's δ as a non-parametric effect size, where δ = 1 means every score in one group exceeds every score in the other. For the hard-fail clearance contrast, a count, we use a Fisher exact test. To test whether the cheap shape metric tracks the expensive correctness metric, we report the Spearman rank correlation between the two scores. All tests run from the committed scores through compute_stats.py with no external statistics library, so a reader can reproduce every number. These tests quantify the separation we observed, and the sample is too small to detect anything but a large effect, which is the honest reading of a study at this scale.
5. Results
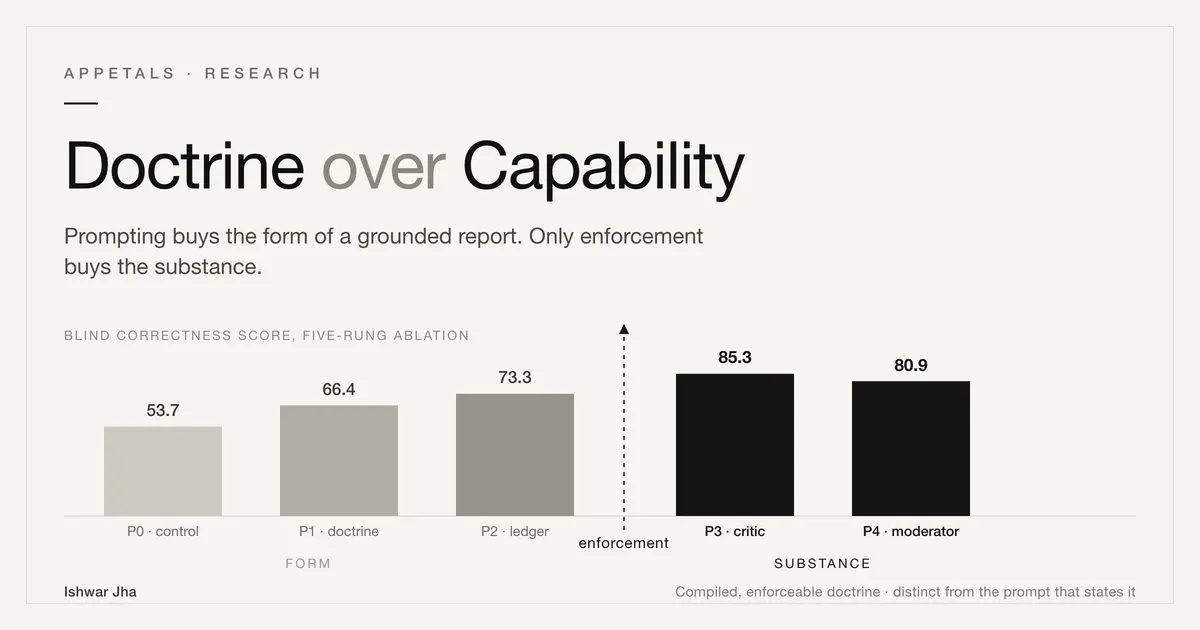
Table 1 consolidates both axes across the ladder. The shape column is the deterministic linter score. The doctrine and the two enforcement rungs are replicated nine times each. The correctness column is the mean of the independent blind judge, who rated the first run of every rung. Hard-fail is the fraction of deliverables that the strict gate blocks.
Rung (adds) | n | Shape mean | 95% CI | Hard-fail | Correctness mean |
|---|---|---|---|---|---|
P0-control (nothing) | 3 | 20.0 | [20.0, 20.0] | 100% | 53.7 |
P1-doctrine (prompt) | 9 | 73.3 | [69.5, 77.2] | 100% | 66.4 |
P2-ledger (state) | 3 | 70.0 | n/a | 100% | 73.3 |
P3-critic (enforcement) | 9 | 81.1 | [76.5, 85.7] | 89% | 85.3 |
P4-moderator (coverage + enforcement) | 9 | 75.6 | [68.8, 82.3] | 78% | 80.9 |
Table 1. Two-axis results. Shape is the deterministic doctrine linter. Correctness is the independent blind judge. The doctrine and enforcement rungs are replicated nine times on both axes. The control and ledger rungs stay at three runs, one per question.
5.1 Significance and effect sizes
The control-to-doctrine gain on the shape axis is significant by an exact permutation test, p = 0.0045 with δ = 1.00, meaning every doctrine run outscored every control run. On the correctness axis, replicated in nine runs for the doctrine and enforcement rungs, the separation is sharper. The pooled enforcement-versus-control contrast is p = 0.0008 with δ = 1.00. Enforcement also beats the doctrine prompt itself: the critic over the prompt at p = 0.0006 and the moderator over the prompt at p = 0.012. The doctrine prompt alone does not significantly beat the control on correctness, p = 0.127. So prompting reliably improves the form of the output, and only enforcement reliably improves how correct it is. The hard-fail clearance rate is the one contrast where replication overturned an early reading. At three runs per enforcement run, the rungs cleared the gate two times in six, a Fisher exact p = 0.071 we had called a trend. At nine runs each, clearance settled at three in eighteen against zero in fifteen, Fisher exact p = 0.233. Enforcement is the only setting that ever clears the strict gate, but it does so rarely and not significantly at this scale. We report the correction rather than the optimistic first reading.
5.2 The doctrine prompt produces a large, stable shape gain
The control sits at 20.0 out of 100 with zero variance. Adding the doctrine prompt moves the score to 73.3 across nine replicate runs, with a standard deviation of 5.0 and a 95% interval of [69.5, 77.2]. The nine runs scored 70 on six of them and 80 on the other three. The interval is tight and sits far above the control, so the jump is a property of the discipline, not of a lucky single run. Two structural markers appear only once the doctrine is present: machine-readable handoff envelopes go from absent to universal, and dual-tier evidence labels go from zero to roughly six per document.
5.3 The gate stays hard, and only enforcement clears it
The hard-fail rate stays pinned at 100% through P1 and P2. The doctrine prompt earns the soft points for confidence bands, triangulation, falsifiability, and bias naming, yet it still trips the strict paragraph-level checks because the model does not label every single quantitative paragraph even when told to. Statefulness does not change this. The non-enforcement rungs cleared the strict gate zero times in fifteen, the enforcement rungs three times in eighteen, and every clearance came on the same question. The critic and moderator do work the prompt cannot, since closing the last paragraph-level gaps needs a checking and revising step rather than a better instruction. What the data do not support is a claim that enforcement reliably produces ship-ready output. A dedicated critic still leaves at least one quantitative paragraph unlabeled most of the time. The strict deterministic gate functions as a forcing function: it almost always blocks, it rarely passes, and in production it usually demands another pass rather than waving work through.
5.4 The shape score is non-monotonic in capability
The ledger rung scores below the prompt rung on the shape axis, 70.0 against 73.3, even though it adds statefulness, and the moderator rung at 75.6 sits below the critic rung at 81.1 even though it adds a coverage pass on top of enforcement. The reason is construct validity. These rungs optimise for things the shape linter does not measure. The ledger adds reproducibility, scaffolding and length. The moderator closes named gaps and corrects errors, which adds quantitative content faster than it adds labels, and the moderator deliverables are the longest in the study at roughly 1374 words. A shape linter can therefore hold flat or fall on a rung that improves coverage and correctness. The study demonstrates the linter's own blind spot using the system's own outputs.
5.5 The blind correctness judge rewards corrections that the shape axis cannot see
The control averages 53.7. The doctrine prompt reaches only 66.4 and is the noisiest rung, with a standard deviation near 12 and scores from 44 to 84, which is why it does not separate from the control. The ledger sits at 73.3. The two enforcement rungs sit clearly above, the moderator at 80.9 and the critic at 85.3, and the critic is the tightest of the upper rungs. The judge, blind to condition, rewarded the exact corrections the enforcement layer made: the brief that self-corrects a conflated revenue figure, the brief that replaces an unsupported churn statistic with the verified one, the brief that re-anchors a survey series to its primary source, and the brief that catches a company name-collision in a funding figure. It penalised prompt-only briefs that carry an unverified rating or an inflated count as fact. These corrections are invisible to the shape linter, which is the empirical case for pairing the two instruments. The doctrine prompt makes the output look right at the level of form, and closing the gap to output that is more correct takes the checking and revising of enforcement.
5.6 Construct validity: the two axes agree on direction but only moderately
Across all thirty-three matched cells, the shape score and the correctness score correlate at Spearman ρ = 0.48. An early estimate on the first fifteen-run cells looked stronger at 0.78, and replication pulled it down, the same lesson the clearance result taught. A moderate positive correlation means the cheap deterministic check captures a real signal and is not noise. It also means the check is far from a substitute for a correctness measure, since most of the variation in how correct a brief is lives outside what a form linter can see.
5.7 Cheaper correctness proxies: grounding and model-based metrics
A blunter deterministic check than the shape linter asks whether each quantitative paragraph carries an inline source at all, what fraction of cited domains look primary, and how much calibration language is present. This grounding metric uses no model. Across the thirty-three cells, it correlates with the blind judge at Spearman ρ = 0.67, higher than the shape linter at 0.48. The enforcement rungs top it as they top correctness, the critic at 60.5 and the moderator at 58.6, while the doctrine prompt scores lowest at 28.1, below the control, because it emits many tier-tagged figures without an inline source on every one. We then built the two model-based instruments that the grounding metric cannot reach. An ALCE-style metric fetches each cited source live and asks an NLI model whether the source entails the claim, so it checks the source the brief cited. A SAFE and FactScore-style metric decomposes each brief into atomic claims and rates each against a fresh web search, so it checks whether the claim is true against the open web. The two diverge sharply. The citation-entailment metric is a weak predictor, Spearman ρ = 0.13, below even the shape linter, and it ranks the ledger rung highest rather than enforcement, because several briefs place sources in a trailing block rather than inline and strict entailment over heterogeneous live pages is brittle. The open-web factuality metric is the opposite, Spearman ρ = 0.59, close to the grounding metric and far above the entailment metric, and it places the critic rung on top at 0.71 supported atomic claims. The supported fraction, which counts an unverifiable claim against the brief, tracks correctness, while the bare support rate among only the decidable claims does not, because a brief earns a high rate by making few checkable claims. The full ordering from weakest to strongest predictor of correctness is the citation-entailment metric (0.13), the shape linter (0.48), the open-web factuality metric (0.59), the grounding metric (0.67), and the blind judge itself. No automated instrument here replaces the judge.
5.8 A six-judge, three-provider panel reproduces the ranking
To check that the correctness result is not an artefact of one judge or one provider, five further judges rated the same fifteen first-run briefs blind under the same rubric. There are Claude models, Opus, Sonnet, and Haiku. Three are from other providers: GPT-4.1, Gemini 2.5 Flash, and GPT-5.5. The two capable Claude judges agree strongly, Pearson r = 0.93 and Spearman ρ = 0.84. The cross-provider judges agree with the Claude panel on rank at Pearson r = 0.56 to 0.85, and the most capable of them, GPT-5.5, agrees with the lead judge Opus at r = 0.83 and ρ = 0.84, the closest any non-Claude judge gets. The six-rater Fleiss κ = 0.13, low because the judges use the scale differently rather than because they disagree on rank. GPT-4.1 compresses toward the ceiling, scoring the control 74 and every treated rung between 92 and 94, so a binned agreement statistic collapses even though its rank order matches. Gemini and GPT-5.5 separate sharply instead, GPT-5.5 scoring the control 30 and the critic 75, much as Opus does, which is why the more capable cross-provider judge tracks the lead judge best. The reliability of a model judge depends on how it uses the scale, not on its provider. What survives all six judges is the ordering. Each judge places the two enforcement rungs in its top two and the control lowest. Across Opus, Sonnet, Haiku, GPT-4.1, Gemini, and GPT-5.5, the critic rung scores 88, 82, 77, 94, 95, and 75, and the control scores 54, 36, 57, 74, 37, and 30. The correctness claim is a claim about ordering, and the ordering is provider-invariant even where the absolute scores are not.
Taken together, the two axes triangulate a precise version of the thesis. On the shape axis, the doctrine prompt produces a large and significant gain at fixed capability. On the correctness axis, replicated in nine runs, the prompt does not significantly beat the control, while enforcement beats both the control and the prompt. Writing the doctrine into the prompt buys the form of a grounded report. Buying the substance takes enforcement. The strict gate earns its keep as a blocker rather than as a step the pipeline reliably passes.
6. Replication on a Second Base Model
The primary study holds the model fixed at one Claude family, which Section 7 names as its main external-validity exposure. To test whether the result is a property of the doctrine or of that one model, we replicate the entire ladder on a different base model, GPT-5.5, reached through a command-line tool with live web search. This is a replication, not an extension of the primary table. Every rung runs on GPT-5.5, so the ablation stays internally valid, and we compare the two studies ordering to ordering rather than cell to cell. We run the same forty-question benchmark, the same five rungs, and score with the same deterministic instruments, and the per-rung prompts are reconstructed from the same doctrine the Claude agents compile in. We report the replication on the two judge-free axes, the deterministic shape linter and the model-free grounding metric, so the numbers reproduce offline. The matched set is all forty questions, run-1, with every one of the five rungs complete.
Rung | GPT-5.5 shape | GPT-5.5 grounding | Hard-fail | Claude shape |
|---|---|---|---|---|
P0-control | 35.5 | 52.9 | 98% | 20.0 |
P1-doctrine | 91.2 | 50.8 | 30% | 73.3 |
P2-ledger | 88.8 | 51.1 | 65% | 70.0 |
P3-critic | 94.5 | 73.8 | 5% | 81.1 |
P4-moderator | 92.5 | 62.9 | 18% | 75.6 |
Table 2. The five-rung ladder replicated on GPT-5.5, matched n = 40, on the two judge-free axes. The Claude shape column is reproduced from Table 1 for comparison.
On the shape axis, the ordering reproduces more sharply than on Claude. The control sits at 35.5, the doctrine prompt at 91.2, and the critic on top at 94.5. The control-to-doctrine gain, 35.5 to 91.2, is completely separated, δ = 1.00, with a Monte-Carlo permutation p < 10⁻⁵, and the control-to-enforcement gain, 35.5 to 93.5, is also δ = 1.00. The model-free grounding metric agrees and puts enforcement on top, the critic at 73.8 and the moderator at 62.9, well above the control, prompt, and ledger rungs that cluster near 50 to 53, with the control-to-enforcement grounding gain 52.9 to 68.3 at δ = 0.71 and p < 10⁻⁵. So, on a second model and on a second judge-free instrument, enforcement again produces the best-grounded output.
One finding is model-invariant, and one is model-dependent. The invariant one is central: writing the doctrine into the prompt produces a large, completely separated shape gain on both models, and enforcement produces the best shape and the best grounding on both. The model-dependent result is gate clearance. On Claude, the strict gate was a near-impassable wall, the prompt clearing it zero times in fifteen and even enforcement only three in eighteen. On GPT-5.5, the same gate is passable: the doctrine prompt clears it on 70% of briefs and the critic on 95%, while only the control reliably hard-fails. The reason is compliance, not capability in the abstract. GPT-5.5 labels more of its quantitative paragraphs with a dual-tier tag, a source, and a date when told to, so the prompt alone gets closer to the bar. This refines the primary claim rather than overturning it: enforcement still yields the best shape, the best grounding, and the highest clearance on both models, but how much enforcement a strict gate requires depends on how compliant the base model already is.
We replicate on the two judge-free axes by design. An independent correctness rating of the GPT-5.5 briefs would ideally come from a different provider than the generator, since a GPT-5.5 judge rating GPT-5.5 output risks self-preference, and the cross-provider judge accounts were rate-limited at the time of writing. We therefore report the replication on shape and grounding, both independent of any judge, and note that the model-free grounding metric is the instrument that best predicted the blind judge in the primary study.
7. Limitations and Threats to Validity
The sample is small, and the field has warned that small samples in language evaluation often fail to support their claims and can exaggerate or reverse a true effect [6]. We take that warning seriously in two ways. We use exact tests and effect sizes rather than approximations, and we restrict our confident claims to the contrasts that show complete separation with a maximal effect size and a permutation p below 0.05, namely the control-to-doctrine gain on the shape axis and the control-to-enforcement gain on correctness. We treat the within-rung rank order among the prompted rungs as unresolved, since those intervals overlap. A study with three questions per cell can show that a large effect exists. It cannot rank close competitors, and we do not try.
This paper demonstrates that a warning is on its own data. Our first reading of the gate-clearance rate, at three runs per enforcement rung, looked like a trend toward enforcement clearing the gate, Fisher exact p = 0.071. Replicating to nine runs each moved the rate down and the p to 0.233, removing the effect. We then replicated the correctness axis to nine runs for the doctrine and enforcement rungs, and it moderated as expected: the doctrine prompt fell from 74.7 to 66.4 and lost its separation from the control, the critic fell from 88.0 to 85.3, and the moderator from 84.0 to 80.9, while the enforcement advantage over the prompt held and stayed significant. The shape-correctness correlation also fell under the larger sample, from 0.78 to 0.48. Two early point estimates moved toward the null under replication, and the two that survived, the shape gain from the prompt and the correctness gain from enforcement, are the ones we build the claims on. We kept the corrections and the history because a paper about cite-or-abstain should hold itself to the same standard.
The treatment prompts request the very scaffolding the shape linter rewards, so the handoff and label gains are partly elicited rather than discovered. The results that survive this objection are the ones the prompt did not ask for: the persistence of hard fails under prompting, the break under enforcement, and the blind correctness ranking.
The shape linter measures form, not truth, by design, and a deliverable can score well and still be wrong. The blind judge addresses this, and we tested its reliability with five further judges across three providers. The smaller Haiku judge agrees less and compresses the scale, which shows that judge capability matters, but all six reproduce the ordering, control the lowest and the two enforcement rungs on top, with cross-provider Pearson r = 0.56 to 0.85. A residual exposure remains that all six are large instruction-tuned models and could in principle, share a deeper blind spot, which is why we also report automated correctness metrics that use no model judge at all.
On scope, retrieval was United States-scoped, and the study covers one domain, startup research, so external validity beyond that domain is untested. The single-model-family exposure is the one we have most directly addressed: Section 6 replicates the whole ladder on GPT-5.5, a model from a different provider trained by a different lab, and the shape and grounding ordering reproduces with complete separation. That replication runs the full forty-question benchmark but at a single run per cell, so it reports breadth rather than within-cell variance, and an independent cross-provider correctness rating of the GPT-5.5 briefs is the one correctness measurement we leave open. The critic and moderator rungs build on a prior brief, which isolates their marginal effect but couples them to that input. We do not price cost: the enforcement rungs add tokens and latency, and a full account would weigh the correctness gain against that cost. We do not claim the specific magnitudes transfer beyond this system and domain. We claim that the direction and the architecture transfer, and the second-model replication, is the first evidence that they do.
8. Discussion
The pattern that recurs across both instruments is that an instruction is not a guarantee. A capable model under explicit doctrine still under-complies at the level of the gate checks, which is why the gate and the critic earn their place. The shape linter and the correctness judge disagree exactly where theory predicts, on the rungs that add coverage and statefulness rather than form. That disagreement is not noise to be smoothed away. It is the reason a doctrine-shaped output and a correct output are different targets, and the reason a serious research agent needs a correctness check that the cheap deterministic gate cannot provide.
There is a practical reading for builders. The cheapest large gain comes from writing the doctrine into the prompt. The gain that actually clears a strict bar comes from enforcement, which is more engineering than prompt. Statefulness and moderation pay off on correctness and coverage, which a form-only metric will under-credit, so a team that optimises only the cheap metric will stop too early.
9. Conclusion
We set out to test whether discipline or capability is the binding constraint on multi-agent research quality, and whether discipline can be enforced rather than merely requested. On a five-rung ladder evaluated by a deterministic shape linter and an independent blind judge, replicated to nine runs, the doctrine prompt produced a large and significant gain on the form of the output, yet did not significantly improve how correct it was. Enforcement improved correctness over both the control and the prompt, and the critic over the prompt at p = 0.0006. A blind judge rewarded the concrete error corrections that a form-only metric never sees, and the ranking held across six judges, three providers, an independent web-search factuality check, and a full replication of the latter on a second base model from a different provider. The contribution is not a larger model and not more agents. It is a written, two-axis evidence doctrine, compiled into a deterministic gate and backed by an independent critic, the part that turns a report that looks grounded into one that is.
References
[1] Yijia Shao, Yucheng Jiang, Theodore A. Kanell, Peter Xu, Omar Khattab, and Monica S. Lam. 2024. Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models. In Proceedings of NAACL 2024. arXiv:2402.14207.
[2] Yucheng Jiang, Yijia Shao, Dekun Ma, Sina J. Semnani, and Monica S. Lam. 2024. Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations. In Proceedings of EMNLP 2024. arXiv:2408.15232.
[3] Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. Enabling Large Language Models to Generate Text with Citations. In Proceedings of EMNLP 2023. arXiv:2305.14627.
[4] Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. In Proceedings of EMNLP 2023. arXiv:2305.14251.
[5] Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, and Quoc V. Le. 2024. Long-form factuality in large language models. In Proceedings of NeurIPS 2024. arXiv:2403.18802.
[6] Dallas Card, Peter Henderson, Urvashi Khandelwal, Robin Jia, Kyle Mahowald, and Dan Jurafsky. 2020. With Little Power Comes Great Responsibility. In Proceedings of EMNLP 2020, pages 9263 to 9274. arXiv:2010.06595.
AI Use Disclosure
This paper studies an AI system and was produced with AI assistance, which we state plainly. The research deliverables that make up the experimental data were generated by the multi-agent system under study and, in the replication, by a second large language model. The manuscript was drafted with the assistance of a large language model. The author defined the study, ran and supervised the experiments, verified every reported number against the committed artefacts, and is responsible for all claims and any errors. The supporting code and the full version history, which records the AI assistance commit by commit, are available at https://github.com/ishwarjha/doctrine-over-capability .